Charge Domain Analog
Charge Domain Analog Processing
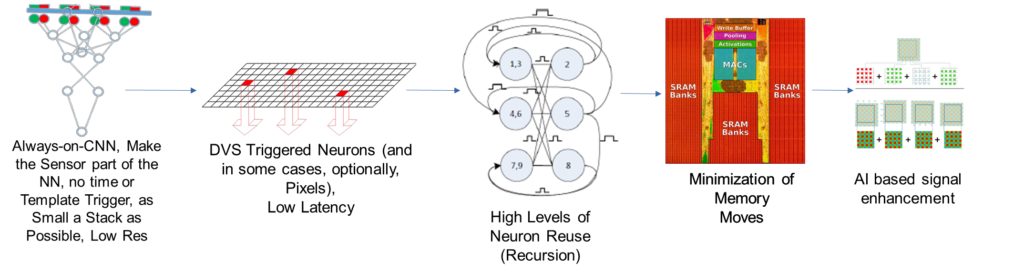
AIStorm is the pioneer of charge domain processing. AI computing is a special type of mathematics, and as such there are multiple approaches to the hardware and software implementations that can perform this special mathematics. We take pains to differentiate our technology from analog processing, process in memory, or neuromorphic processing as it is different. AIStorm’s methods are also very different to digital processing by CPUs or GPUs. Although charge domain processing shares some of the benefits of these other methods, the implementation is done very differently. In the figure above we illustrate some of our biggest advantages: i) making the sensor part of the neural network; ii) only waking up circuits that need to be awake; iii) recursion; iv) minimizing memory; v) performing ISP and spectral conversion using charge domain techniques.
The Cost Advantage. AIStorm’s ability to replace weights at the speed of execution and its charge domain technology allows recursive operation which dramatically reduces silicon use compared to PIM solutions, and its high execution speed and limited number of cycles per layer means that memory requirements are dramatically reduced compared to digital. We pass the resulting savings in silicon area on to you, with costs often 5x lower than PIM or digital alternatives. Additionally, our “real always on” makes the sensor part of the neural network, allowing continuous AI operation in busy environments which no other AI can offer, and our AI-in-Sensor devices even include the sensors such as the pixel array monolithically to minimize solution cost and size.
The Recursive Advantage. AIStorm’s neurons communicate with each other through a pulse based switch matrix. Additionally, weights can be setup quickly enough that different weights are possible each and every cycle. This is very different to digital or GPU solutions which might take thousands of cycles to perform the same calculations that charge domain can execute in one cycle. It is therefore possible re-use a small number of neurons as if they were a large network of millions of neurons, as further illustrated in the figure on the right. In this figure three layers of neurons are executed using six neurons by re-using the first layer of neurons.AIStorm’s neurons have time constants in the nanoseconds and can perform up to 1024 simultaneous fused multiply and add operations.
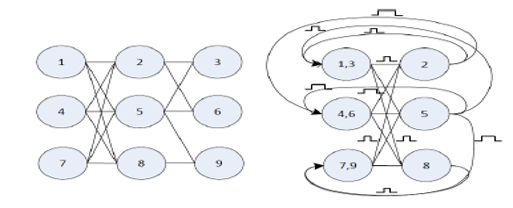
It would take 100’s of Gigahertz for a digital system to execute such an inference in the same time as AIStorm’s charge domain implementation. In fact if we consider a time constant of 10ns, then in a typical network with a 150ms execution time we could re-use our neurons 15 million times. The result is that we can reduce the amount of silicon required for a neural network dramatically compared to either digital or PIM solutions and pass that savings back to the customer.
ADC or Interface Conversions Not Required. Digital edge solutions require sensor information to be converted to digital values before they can process the information, while PIM solutions boasts of tens of thousands of analog to digital converters setting up their interface elements. ADCs take silicon area, time to convert and cost money. AIStorm’s charge domain technology accepts input pulses and produces output pulses compatible with downstream neurons without special ADCs or interface devices, saving both time and silicon area.
The Efficiency Advantage. The charge domain is a much lower noise environment than the analog environment. To maintain the signal to noise ratio (SNR) required to produce a given accuracy, the noise floor (given in number of electrons) must be the same multiple in any domain. As such PIM and digital solutions require far more electrons than charge domain solutions do. This allows AIStorm to use fewer electrons in our solutions, which require less space and therefore our ICs are more dense in a given node. Additionally, it takes less time to move fewer electrons and since power is charge moving through a potential in a given time, therefore it also translates into significantly lower power. In fact charge domain solutions can attain overall system efficiencies from 30-250 TOPS/W far beyond what is possible with PIM or digital solutions.
The PVT Advantage. AIStorm’s processors multiply charge, rather than work with current or voltage. This brings several advantages: i) AIStorm’s neurons can accept sensor information directly; ii) process and temperature variation are divided out. Unlike PIM solutions which are very process dependent, even requiring temperature controlled environments within a few degrees, as well as significant calibration, charge domain solutions are process independent. This is possible because charge is not dependent upon the well in which it is stored. As an example, if charge is stored on a capacitor its voltage will change depending
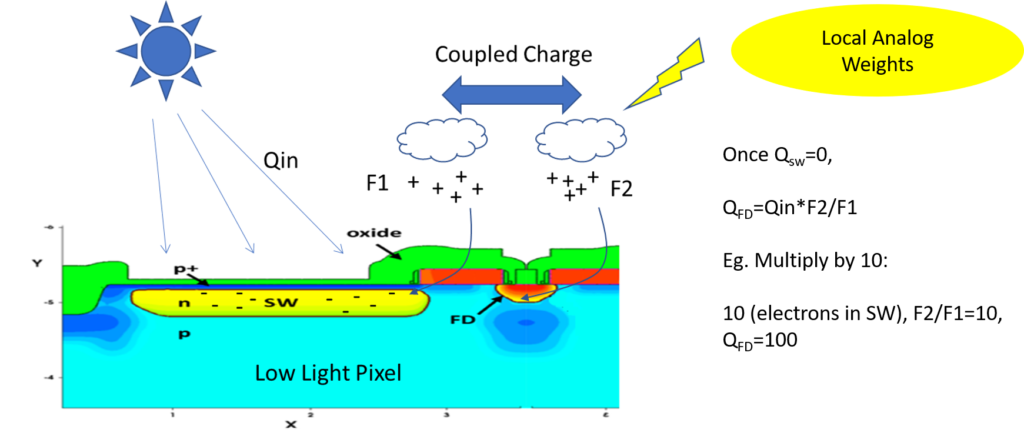
on the capacitor value. This is a limitation on switched capacitor circuits. On the other hand five electrons is five electrons regardless of the capacitor value in a charge domain circuit. Thus it is not a limitation on charge multiplying circuits. In the figure a storage well resulting from exposure to light (a pixel) is discharged at a rate which is a multiplicand of the rate of filling of another well (a floating diffusion). As we can accurately control the ratio between these rates of charge movement we can therefore multiply charge very effectively. In fact the topologies are also compatible with oversampling error feedback schemes which allows AIStorm’s charge domain solutions to produce precisions that are not possible with PIM. Compared to the amount of calibration required for PIM solutions, significant money can also be saved during package and test.
AI-in-Sensor & Real Always-On. AIStorm can accept charge information directly from pixels or other charge based devices such as microphones. Neither digital nor PIM can do that. In fact both digital and PIM require conversion of input information into another form – digital requires digital values and PIM requires information compatible with its input elements. There is significant latency involved with these conversions, as well as power wasted, but more critically it means that neither methodology can provide “real always on”. This is because it is not efficient to convert all incoming information in edge applications and therefore some sort of “trigger” for example based upon pixel changes or other unintelligent metric must be used to decide when to trigger the digital or PIM systems to perform an AI inference. AIStorm on the other hand makes the sensor input, such as pixels, part of the neural network and therefore it is the only AI which can operate AI continuously, improving dramatically the quality of the always on monitoring and reducing false alerts and associated power use. Many of AIStorm’s devices are monolithic, meaning the sensor is included on the same chip saving cost and minimizing area.
Speed. AIStorm’s AI is very fast. Up to several hundred GHz would be required by a digital system to keep up with certain instructions. As such it can keep up with applications such as power and RF in a serial fashion which no other AI can do. Further, AIStorm can output pixel information more quickly than other methods and has imagers operating up to 260,000 frames per second for machine vision and other applications.

Background
To better understand the differences between approaches to AI processing we introduce the “three domains.” The charge domain is a unique domain that many years ago was a candidate for processor design, but was overtaken at the time by transistor based digital implementations, and which has since been relegated primarily for use primarily in image sensors. This domain is a very low noise domain, with systems capable of measuring the light from distant stars, or moving charge with precision that is impossible in other domains. The analog domain is a domain of transistors, capacitors, resistors and similar components where voltages and currents are manipulated using the transfer functions of these components. Finally, the digital domain is a subset of the analog domain where transistors are used as switches to implement digital transfer functions. AIStorm operates in the charge domain and in hybrid charge domain-analog implementations that are unique to any other method of performing AI. AIStorm has been working on these solutions for many years and holds a significant patent portfolio protecting these innovations.
Digital AI Processing
Digital AI processing is the market leader. It is common to hear that “there are so many AI hardware companies out there,” however, in reality these tend to be companies modifying base implementations from ARM or other IP makers rather than whole new ways to implement AI. Digital implementations take advantage of an infrastructure built over many years to service personal computers and gaming. As such Digital AI processing was well positioned to rapidly satisfy the growing expansion of AI applications when it appeared. Digital AI can be performed by CPUs or GPUs. CPUs tend to be poor at AI due to their lack of parallelism, while GPUs are efficient mathematical engines designed to perform large numbers of parallel calculations and as such they are a good and available method for executing large AI functions. Unfortunately, AI processing has several major disadvantages:
The Memory Problem. The figure to the right illustrates one of the biggest disadvantages of transistor based digital processing. In red are the SRAM memory banks of this GPU implementation (courtesy Tesla Corporation). It can be seen that although this chip is said to be an AI chip, in reality it is a memory chip with some AI on board (MACs, Activitations, Pooling). Digital AI chips are dominated by memory and the interconnects to take information from the

computing cores (MACs) to and from that memory. There is also a theoretical limit, called the von Neumann bottleneck, that is a limit to the processing capability of a digital circuit.
The Efficiency Problem. The moving of information between computing elements uses a lot of power, as do the many instructions required to simulate a neuron. As such digital implementations represent some of the least efficient implementations for AI possible. Generally, in the smallest most expensive processes, digital AI operates between 0.8-5 TOPS/W (a measure of efficiency).
The Cost Problem. Due to their ability to parallel very large numbers of simultaneous computations, digital implementations can be stretched to handle large tasks at the price of die area or by using expensive small lithography processes.
The Parallelism Problem. There are many problems that can be broken up and parallelized, but there are many than can not. Additionally, there is overhead associated with organizing information for GPU elements to perform those parallel calculations. The power and complexity associated with the organizing of this information (called systolics) is itself a user of computing resources and power, and it is often impossible to divide a problem up efficiently pushing real world performance far from its advertised peak. For those applications not well suited to being broken up into parallel streams, digital solutions are very poor. For example, they are incapable of keeping up with RF or power tasks, or activities that must be serially computed.
Process in Memory
A technology which attempts to overcome the memory disadvantages of digital implementations is called process in memory. The idea here is to use special devices embedded in the calculation engine to perform the mathematics. These devices set the “weights” in a neural network and since they are embedded in the calculation matrix the solution is considered “in memory.” Generally, these devices are resistors which can be implemented in a variety of ways including: i) memristors; ii) magnetic memory; iii) NVM; iv) current sources. The input elements are voltage sources or current sources, and similarly the result is a voltage or a current. These type of circuits have been implemented as small AI extensions to microcontrollers and as complex deep networks and have been shown to be able to handle reasonable AI loads. PIM efficiencies with constrained (application specific) implementations have been shown to reach as much as 25 TOPS/W but more typical results are in the 2 TOPS/W range.

The Stranded Silicon Problem. Most PIM based solutions rely on elements that take a lot of time to set and which can only be changed a limited number of times. As such they tend to have fixed weight parameters which are not changed. For example a 5×5 kernel might be loaded with weight values that are stepped across an image, however, once complete these elements can no longer be used. This means that for a pipelined structure only part of the silicon will be active, and that which has finished its function and therefore unused is considered “stranded.” Silicon area efficiency is therefore poor.
The Noise Problem. Resistors are known to be noisy devices. Specifically, they introduce noise such as 4kRT thermal noise. This noise puts an effective limit on the precision possible with PIM solutions – maxing out at six and usually fewer bits when distortion is considered.
The Speed Problem. Each node within a PIM matrix has a capacitance and resistance associated with it. As the values of resistors can become large to keep currents small, therefore the RC time constants can also be large. Additionally, transconductors or other finite bandwidth elements used to sum the currents (for example) have a finite bandwidth which puts a cap on settling time and network speed. The need for these finite bandwidth elements also produces a headroom issue limiting the ability for PIM solutions to scale to deep submicron processes.
The Dynamic Range/PVT/Distortion Problem. The resistors used in PIM solutions vary with temperature and process. As such it is necessary to control temperature or spend significant resources on calibration, for example by introducing lookup tables and other calibrations at the time of packaging. This adds cost. To minimize currents in the network it is desirable to minimize the dynamic range of resistors, and often logarithmic or other schemes are used which are sensitive and cause even more distortion and make calibration take even longer. Correcting for these distortions typically means that PIM solutions cannot offer the same accuracies as digital implementations for an overall inference.
The Cost Advantage. AIStorm’s ability to replace weights at the speed of execution and its charge domain technology allows recursive operation which dramatically reduces silicon use compared to PIM solutions, and its high execution speed and limited number of cycles per layer means that memory requirements are dramatically reduced compared to digital. We pass those savings on to you, with costs often 5x lower than PIM or digital alternatives.
MantisNet Models
Programming embedded systems with their limited resources is a challenge for engineers transitioning from PC based systems whether those embedded solutions be digital, PIM or charge domain. AIStorm therefore offers a number of pre-developed solutions for common problems that may be used by customers to quickly implement solutions using its Cheetah, Mantis or Chimera platforms. These solutions are generally called MantisNet implementations. Models exist for applications from face recognition, to face detect, to key word spotting and many others. Please see the solutions and product specific pages for more information.

The device includes three pre-defined structures that are commonly used for applications such as, people detection, people counting, object classification, etc. It includes two convolutional clusters and a fully connected cluster. The figure about illustrates the flexibility in the structure of the MantisNet clusters.